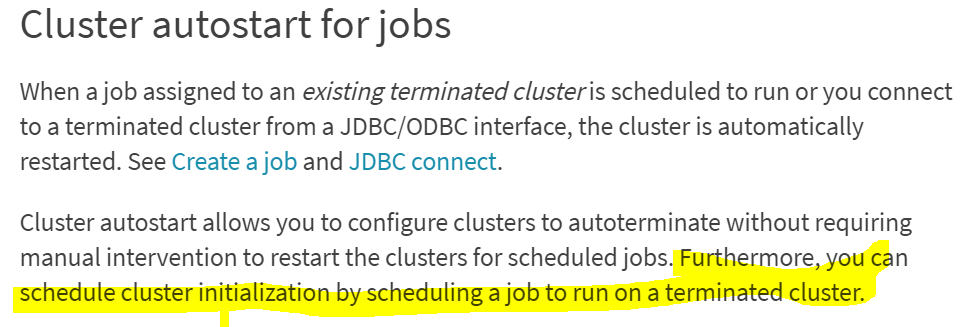
1. Good Foundational Knowledge of SQL Programming (SQL Query writing)
Paid Course
The best SQL course that I know. (I have not affiliation to the owner). I took this course it has been crucial to my success. It goes from beginner all the way to expert. It is not free. Cost $99http://www.learnitfirst.com/Course/160/SQL-Queries-2008.aspx
Course Video hours: 50hrs
My estimated learning and absorption time: 1 to 3 months
Cheaper option
The Complete SQL Bootcamp 2020: Go from Zero to Hero in Udemy
This is a good first step to get you from beginner to intermediate
Cost 11 dollars
SQL - Beyond The Basics
This course focuses on advanced concepts that are crucial in getting through most interviews these days
Cost 11 dollars
Free SQL course alternatives
Beginner Crash course: https://www.youtube.com/watch?v=9Pzj7Aj25lwAdvanced and more comprehensive videos ;
https://youtu.be/HXV3zeQKqGY
https://youtu.be/2Fn0WAyZV0E
Course Video hours: 7 hrs
My estimated Time to learn: 1 to 3 weeks
2. Knowledge of Python Programming Knowledge (only applies if you do not have any programming background)
1. Beginner / Basic Programming in Python:
I have not watched this but I skimmed through and it looks detailed for anyone brand new to programming or programming in python
2. Intermediate level: Python Data structures
This will go over a lot of the common data structures in python on when to use which and their common capabilities
3. Intermediate level: Python Algorithms
This is helpful to go through various most common algorithms in interview questions using python.
4. Python for Data Analysis: Panda's Dataframe
Course Video hours:13 hrs
My estimated Learning time: 1 month (A lot of time will be spent trying to practice)
3. Good understanding of ETL Computing Engine for Big Data- Spark/Databricks
1. Create a Databricks community edition account so you can have a platform to practice
2. Understand Spark architecture and the overall capabilities of Spark
3. Pyspark Tutorial- Knowledge of SQL and Python would really make learning Pyspark very easy
4. Databricks /Spark Optimization: this is important because a lot of interviews ask about this
Note that if you have good knowledge of SQL and Python you can work a lot with Spark
Total Course Hours: 12 hrs
My estimated Learning hours: 2 weeks
4. Cloud Knowledge AWS or AZURE; Get Certified if possible
Azure AZ-900: fundamental of Azure
AWS Solution Architect: Fundamentals of AWS
Pick one
Total Course Hours: 6-10 hrs
My estimated Learning Time: 1 week
5. Basics of Data Modelling: For Data engineers that need to work more with Business intelligence use cases
Total Hours: 2 hrs
My estimated Learning hours : 5hrs
Summary
Getting into a Data Engineering career is not easy but I believe hard work and dedication can get you there. If you dedicate 3 months of the absolute focus of learning for 4 to 5 hrs a day or 30 hrs a week, you can master most of these fundamental skills and start getting entry-level jobs
I would spend 1 month in SQL,1 month in Python and last month in Spark, Cloud, and Data Modelling
There is a lot more to learn and I have another blog that listed comprehensively all the various tools and technologies a Data Engineer could have http://plsqlandssisheadaches.blogspot.com/2020/01/how-i-transitioned-to-data-engineer-as.html